
一、Heap
1.1 基本觀念介紹
Heap 有兩種分為資料結構和記憶體,都是取累積傾向的意思,而這邊要講的是資料結構的 Heap。

Heap 常見的實作為 Binary Heap,它的樹為 complete binary tree (完全二元樹) 如上圖。一棵依序節點可以從上到下、從左到右的表示為 1, 3, 6, 5, 9, 8。如果刪掉 node 9 那麼這便不是棵完全二元樹;如果拿掉 node 8 仍然是棵完全二元樹,因為整棵樹仍然可以從上到下、從左到右的表示成 1, 3, 6, 5, 9。
- 新增節點時優先從左到右填滿階層後才往下一層
- 概念基於 binary Tree,每個 node 下面最多只會有兩個 child,也有可能是一個或沒有
- 常使用 array 來實作,由左至右、由上到下表示出一個完全二元樹
- 若目前的 node 的 index 是 i,left child node 的 index 就是 i * 2 + 1,right child node 的 index 是 i * 2 + 2
1.2 Max heap
若所有 parent nodes 全部都大於自己的 child nodes時,且為一棵完全二元樹時,我們稱其為 max heap (最大堆積)。
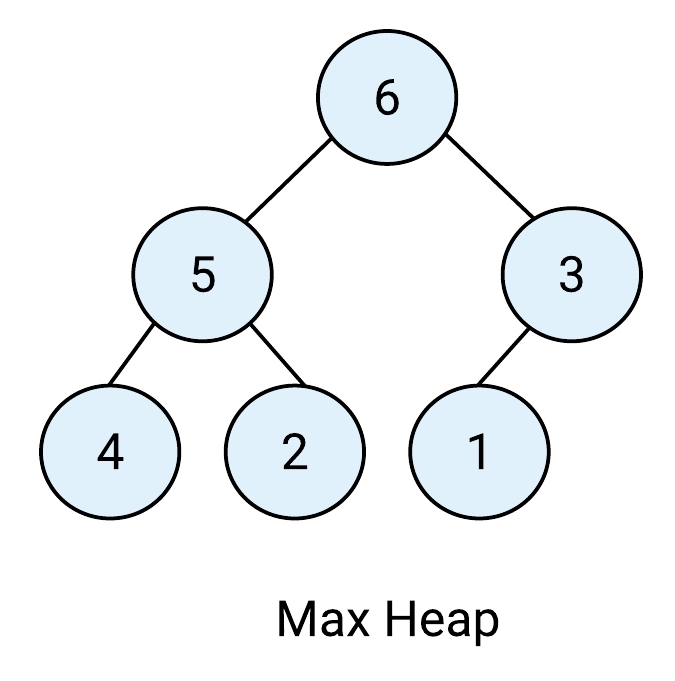
假設我們現在有個陣列資料要將其遞增排序,會先將陣列用完全二元樹的結構來表示如下 :
90
/ \
57 30
/ \ / \
38 9 2 55
/ \ /
41 44 79
再來要將這個完全二元樹 Heapify (堆積化) 變成 Max heap ,建 heap 有兩種方向,一個是由上而下檢查,一個是由下而上檢查。
由上而下檢查又分為兩種方式,一種是由樹根開始,與其左右節點比較;一種是由樹根開始,先找出下一個階層最大的節點,再與樹根比較。
由下而上檢查則是先取得整棵樹的節點數,從最後一個有子節點的父節點做向下檢查,如果子節點比父節點大,那麼就互換;之所以從最後一個有子節點的父節點做向下檢查,是因為最後一層都是葉節點沒有子節點,所以向下檢查是沒有意義的。
這邊採用由下而上檢查的順率,這裡可以看到像是葉節點如 41、44、79 底下就沒有可以交換的子節點。
90
/ \
57 30
/ \ / \
38 9 2 55
/ \ /
41* 44* 79*
再來看到 38 有兩個子節點 41 和 44,由於 44 比 38 大所以就要往上交換,此時 38 已沒有子節點了,結束交換。
90
/ \
57 30
/ \ / \
38* 9 2 55
/ \ /
41 44↑ 79
再來看到 9 有個子節點 79 ,因為 79 比 9 大,所以要交換。
90
/ \
57 30
/ \ / \
44 9* 2 55
/ \ /
41 38 79↑
依此類推,最後建構完的 Max heap 如下。
90
/ \
79 55
/ \ / \
44 57 2 30
/ \ /
41 38 9
接下來的工作就是排序,因為要把陣列做遞增排列。所以我們可以直接把頂層的節點,也就是最大值與陣列的最後一個元素做交換。
9*
/ \
79 55
/ \ / \
44 57 2 30
/ \ /
41 38 90*
在做排序同時也要顧及維持 Max heap,由於此時 90 已經在陣列的正確位置上,我們可以直接把它從最大堆積的考慮範圍中排除。
79*
/ \
9* 55
/ \ / \
44 57 2 30
/ \ /
41 38 90
79
/ \
57* 55
/ \ / \
44 9* 2 30
/ \ /
41 38 90
接下來再繼續重複把頂層的節點 79 和 38 交換,依序執行上續步驟直到完成排序。
38*
/ \
57 55
/ \ / \
44 9 2 30
/ \ /
41 79* 90
2
/ \
9 30
/ \ / \
38 41 44 55
/ \ /
57 79 90
1.3 Min heap
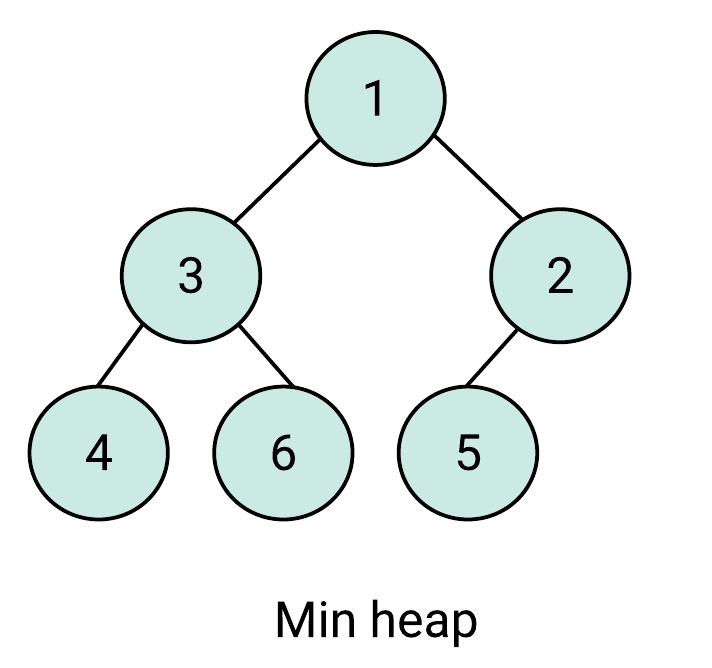
若所有 parent nodes 全部都小於自己的 child nodes 時,且為一棵完全二元樹時,我們稱其為 min heap (最小堆積)。
實作方式同 max heap。
1.4 Insert
90
/ \
79 55
/ \ / \
44 57 2 30
/ \ / \
41 38 9 66*
我們現在有個 max heap,如要新增一個 node 66,則要按照完整二元樹的方式加入節點,優先從左到右填滿階層後才往下一層,新增完後因為 66 > 57 不符合 max heap 所以要如前所述再進行整理。
1.5 Delete
我們現在有個 max heap,如要刪除 node 44,以最後一個節點 9 來代替要被刪除的節點,並由上往下整理 (因為通常會向上替代,除非刪除的是最後一個節點)。
90
/ \
79 55
/ \ / \
44* 57 2 30
/ \ /
41 38 9↑
1.6 實際運用範例

- Heap 可以拿來做 heap sort、Dijkstra’s algorithm
- Heap sort (堆積排序法) 是利用 heap (如 max heap, min heap) 去 sort
- Heap 常用來實作 priority queue,常用於實作 Dijkstra’s algorithm
- Dijkstra’s algorithm (戴克斯特拉演算法) 拿來求最短路徑 = priority queue + BFS
- Priority queue 和一般的 queue 不同,一般的 queue 一定是先進先出,但 priority queue 是有權重關係的
- 另外也是解決 k-th largest problem 很實用的資料結構
二、題目整理

- 題號 : 根據 LeetCode 題目出現的頻率, top interview 150 等整理的,但注意不代表這就涵蓋所有面試會考的題目。或你可以選擇 Grind 來安排你要刷的題目
- 難度 : 按照你現在想要的難度選擇刷題
- 重要性 : 比如說你注意到、或別人提到 Google 很常考這個題目之類,可以設定你覺得相對的重要性,之後可以拿來篩選用
- 第一次是否解出來 : 紀錄解題是否第一次就成功,若不成功可能需要複習
- 解題思路 : 題目的思路過程,寫大綱就好不用寫很詳細
- 其他解法 : 若解出來是否還可以想到其他解法,或是看到別人提供了更好的解法便記錄下來,在面試時還可以提出自己有不同解法
- 學到技巧 : 如此題可以用 two pointer 來解,寫下來下次遇到別的題目就可以知道說我多一個解法可以想想看可不可行
- 複習次數 : 用來記錄第一次解不出來的題目之練習次數
- 複習筆記 : 有可能再做一次還是解不出來,那可寫下這次癥結點是什麼,怎麼解決的,盡量完全理解解法,讓自己如果再做一次題目時若還是卡住,可以看筆記或是回想筆記試圖解出來
- 上次解題時間 : 可用來篩選下次該複習的題目
三、References
相關文章
- Coding Interview 就是刷好刷滿刷爆 LeetCode 就會上?
- 簡單輕鬆十分鐘看懂 Time complexity & Space complexity 分析刷 LeetCode
- 簡單輕鬆十分鐘學會 Hash Map (雜湊表) 刷 LeetCode
- 簡單輕鬆十分鐘 Linked List (鍊表) 刷 LeetCode
- 簡單輕鬆十分鐘學會 Recursion (遞迴) 刷 LeetCode
- 簡單輕鬆十分鐘學會 Stack & Queue (堆疊 & 佇列) 刷 LeetCode
- 簡單輕鬆十分鐘學會 Tree & Binary tree & Binary search tree 刷 LeetCode
沒有留言:
張貼留言
注意:只有此網誌的成員可以留言。